
4 min read

Our big bet when we started Videate was that text to speech (TTS) would keep getting better, eventually becoming indistinguishable from human speech.
This founding principle drove us to keep chipping away at other aspects of the problem: like making an engine that can render software videos with automation that is human-like, homogeneous, and scalable.
The “Brand Voice” Journey
While there are a ton of options available for TTS voices, some businesses prefer to have a voice unique to them. Just like strategically determining tone and visual identity, having a specific, proprietary voice becomes part of the brand. We predict this need for “brand voices” will grow significantly over the next few years.
Just two years back, achieving a brand voice was categorically out of reach for most people, with the process costing well into the six figures range. However, we’ve since seen time-to-value increase several magnitudes.
Recently, we produced a brand voice with Microsoft Cognitive Services, and we wanted to relay some of the trials and tribulations of that process.
We sat down with Dave Gullo, co-founder and CEO of Videate–and now our new brand voice– to find out how he did it.
How we built our realistic text to speech voice with Microsoft Cognitive Services
The requirements
To build a custom brand voice, you need a person to record about 2,000 samples of their speech.
Microsoft requires 1,000 general phrases (provided by them) plus 1,000 phrases and words derived from our customers’ documents.
The samples also include 10% exclamations and 10% questions, which help train the voice engine on different inflections of the voice talent.
Starting the recording process: it’s gotta be QUIET!

Not just library quiet, but < -70db quiet.
This can be a challenge.
Things like refrigerators, air conditioning, thunder storms, vehicles outside, dogs barking, leaf blowers, crying babies, etc., make it difficult to get a clean recording.
The first step was to order acoustic foam from Amazon, and to get (4) 4x8 sheets of thin, oak plywood to build an ad-hoc sound booth.
It’s designed for sitting and easy storage, so I cut it down to 6’ 3” to be a little taller than when I’m standing up.
You’ll notice one of the foam sections popping off. It was necessary to keep around a staple gun during the entire project as a tile would randomly try to escape the backing. But, this is far better than using spray adhesive, which failed
us when buffering offices in the past– it fouls the foam to a point where you never want to use it again.
Rather than clone Dave, we wrote an app for voice recording
Microsoft recommends that you have a professional recording studio and 3 individuals:
- voice talent,
- producer
- and an audio engineer.
There are strict requirements for the sound levels. Our app checks these on both the client and server side and requires that the start/end silence are adequate, therefore fewer samples were rejected on the server-side.
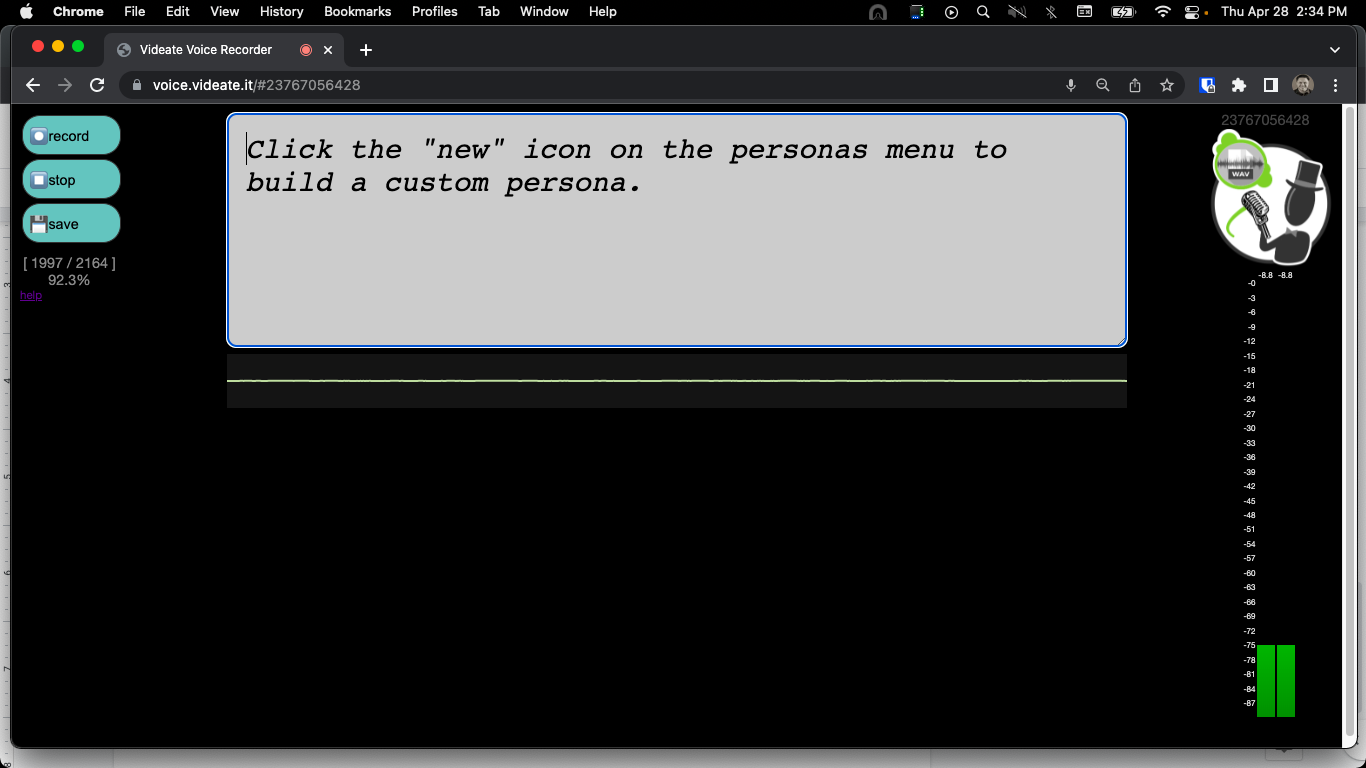
When simultaneously acting as the voice talent, producer, and audio engineer, you simply can’t catch all the flaws, such as adding extra words like “that, this, that… etc”, in spite of the app auto-previewing the audio before saving. When recording hundreds of samples in a session, fatigue sets in, your mind starts to play tricks on you, and mistakes happen.
Luckily, the Microsoft side scores samples. They’ll tell you when it scores poorly, and then our app will delete the take, and prompt you to re-record it in your next session. Early on, the retake rate would be ~10%, but as I got used to the process, I got down to 1-2% by the end.
You have to go slow to go fast.
If we find enough customer interest, we may announce hosting our app for free in the future.
Get a good mic
In the first iteration of the recording project, I found a decent sound booth in a co-working space. I used a Blue Yeti mic tuned with the appropriate cardioid pattern along with proper gain control.
This made decent quality, but I decided it would be easier to do this at home rather than have to continually schedule time at this office. So I moved out of that space and built the home sound booth.
Unfortunately, I had to scrap the first 750 samples because the “presence” of the sound in the co-working space was different from the home sound booth and would cause odd artifacts in the end product.
But on the bright side, a sound test on my M1 Macbook Pro actually performed better at picking up the mid and low tones of my voice. So our new “TTS Dave” voice was generated from a stock laptop microphone.
My audiophile friends are in disbelief!
The final brand voice
Once the requisite 2,000 samples were uploaded, it took ~38 hours of processing time. Within just about one day we had our first 100 speech samples, and they blew our minds.
Videators already familiar with my voice were completely shocked. The new AI-generated neural voice matched my exact timbre, pacing, and intonation. And it was saying net-new phrases, sentences and words not recorded in my homemade sound booth but generated by the TTS engine.
Additional tips for recording your own realistic text to speech voice at home
- Make sure the environment around you is as homogenous as possible. Do not record when it’s windy outside or when the AC is on.
- Be mindful of your posture, and relax. I found that varying energy levels (ie. from mood, intensity, etc.) can easily overwhelm the mic, and our app stops recording from peaking above -3db.
- Don’t record when hungry (or hangry) or right after eating. Since the booth is so quiet and mic so sensitive, it actually picks up the slightest sounds, like stomach growling.
The future of our brand voice
Some people have expressed concern with over-familiarity of the most popular voices on the market. If you’ve heard enough of these voices, you start to hear them everywhere.
As we reproduce our videos with automation using this new brand voice, we hope to show current and future customers just how possible it is now to produce your own unique text to speech voices so you can stand out from the competition.
Stay tuned!

.png)
